


黑娃聊检索·合享(incopat)数据库部分功能简介(2)
发布时间:2021.02.21 福建省查看:3325 评论:0
我的公众号原文链接:https://mp.weixin.qq.com/s/v4NmWZP7OT35gO81Xo1_XA

我在上期文章——“合享(incopat)数据库部分功能简介(1)”中简单介绍了合享数据库的超级排序功能。稍微两句话回顾一下超级排序为何:“我们输入了一些要素想进行检索,同时再输入另一些要素作为检索结果的排序依据,让检索结果按照与另一些要素的相关性降序排列,进一步转述成人话就是,我整了个检索式,但我想优先看到与要素A相关的专利。”
回顾完毕。接下来本文将开始简介一下合享数据库的语义检索功能。
语义检索实际上是任何商业数据库(如智慧芽、patentics、黑马)都有的功能,甚至也会出现在少数的免费数据库中(如专利汇)。那么什么是语义检索呢?我援引北京审协朋友的一篇文章《智能语义检索在专利检索的实战分析》中的一段话来粗粗解释一下:(对语义检索有兴趣的也可以看看这一篇文章的全文内容)
“incopat的语义检索采用了国际领先的深度学习算法,支持输入一段话,系统自动匹配相关专利,查询专利将更轻松、更全面。incopat智能语义检索和patentics智能语义检索的检索原理类似,均需训练得到语义模型。”
简单说就是你输入某个要素,或是专利号或是文本,数据库就会自动匹配一些与之相似的文献出来给你瞧瞧。而相似与否都有个度,有特别像的也有四不像的,实际的检索结果通常都比较庞大,因此大多数数据库都采取了限量浏览的逻辑。以下是合享数据库对于语义检索的操作介绍:
我在上期文章——“合享(incopat)数据库部分功能简介(1)”中简单介绍了合享数据库的超级排序功能。稍微两句话回顾一下超级排序为何:“我们输入了一些要素想进行检索,同时再输入另一些要素作为检索结果的排序依据,让检索结果按照与另一些要素的相关性降序排列,进一步转述成人话就是,我整了个检索式,但我想优先看到与要素A相关的专利。”
回顾完毕。接下来本文将开始简介一下合享数据库的语义检索功能。
语义检索实际上是任何商业数据库(如智慧芽、patentics、黑马)都有的功能,甚至也会出现在少数的免费数据库中(如专利汇)。那么什么是语义检索呢?我援引北京审协朋友的一篇文章《智能语义检索在专利检索的实战分析》中的一段话来粗粗解释一下:(对语义检索有兴趣的也可以看看这一篇文章的全文内容)
“incopat的语义检索采用了国际领先的深度学习算法,支持输入一段话,系统自动匹配相关专利,查询专利将更轻松、更全面。incopat智能语义检索和patentics智能语义检索的检索原理类似,均需训练得到语义模型。”
简单说就是你输入某个要素,或是专利号或是文本,数据库就会自动匹配一些与之相似的文献出来给你瞧瞧。而相似与否都有个度,有特别像的也有四不像的,实际的检索结果通常都比较庞大,因此大多数数据库都采取了限量浏览的逻辑。以下是合享数据库对于语义检索的操作介绍:
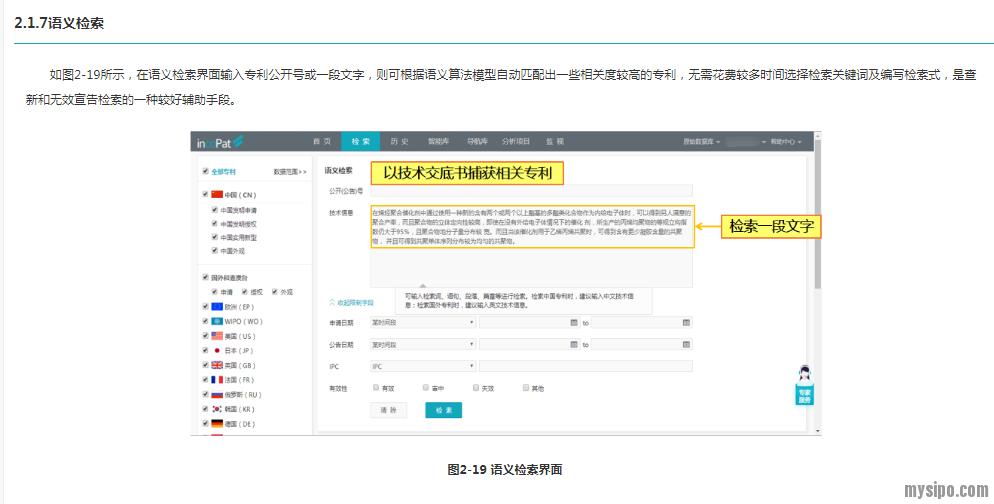
以下是我自己的操作示例:
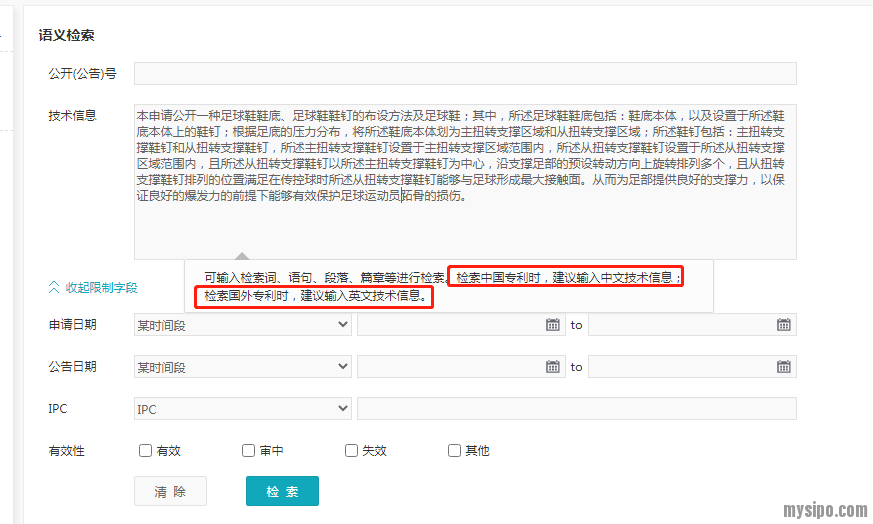
可以看到,专利号以及任何文本形式内容,都可以输入进去进行检索。可以说是非常自由的一种检索功能。
在这里需要注意上图红框部分文字,浓缩语句就是“建议在检索中国专利时用中文,检索国外时用英文”。这不是说我们输入中文,检索结果就只有中文,我们输入英文,检索结果就只有国外专利,要知道合享是自带标题摘要机翻的,我们输入中文也能依靠机翻来检到国外专利。这里的意思是用相对应的文字去输入,系统更能匹配到相似的专利。这个道理与,关键词检索时输入自己查找选取后的外文关键词比仅仅依靠机翻要精确是相通的。
我们看到,语义检索的初始界面还可以设置申请日期/公告日期范围、分类号及待检索对象的法律状态。但在这个初始界面,我们只能设置IPC分类号,不能设置别的分类号。
在这里需要注意上图红框部分文字,浓缩语句就是“建议在检索中国专利时用中文,检索国外时用英文”。这不是说我们输入中文,检索结果就只有中文,我们输入英文,检索结果就只有国外专利,要知道合享是自带标题摘要机翻的,我们输入中文也能依靠机翻来检到国外专利。这里的意思是用相对应的文字去输入,系统更能匹配到相似的专利。这个道理与,关键词检索时输入自己查找选取后的外文关键词比仅仅依靠机翻要精确是相通的。
我们看到,语义检索的初始界面还可以设置申请日期/公告日期范围、分类号及待检索对象的法律状态。但在这个初始界面,我们只能设置IPC分类号,不能设置别的分类号。
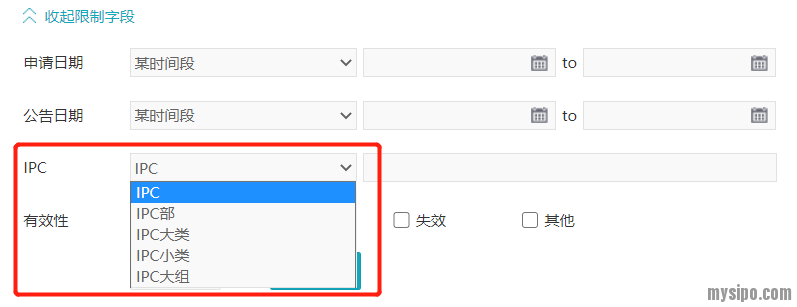
然而,当我们进入检索结果浏览界面,点击二次检索就可以另外设置EC、UC、FI、FT或LOC了。要注意这里的主动选择项并不包括CPC:
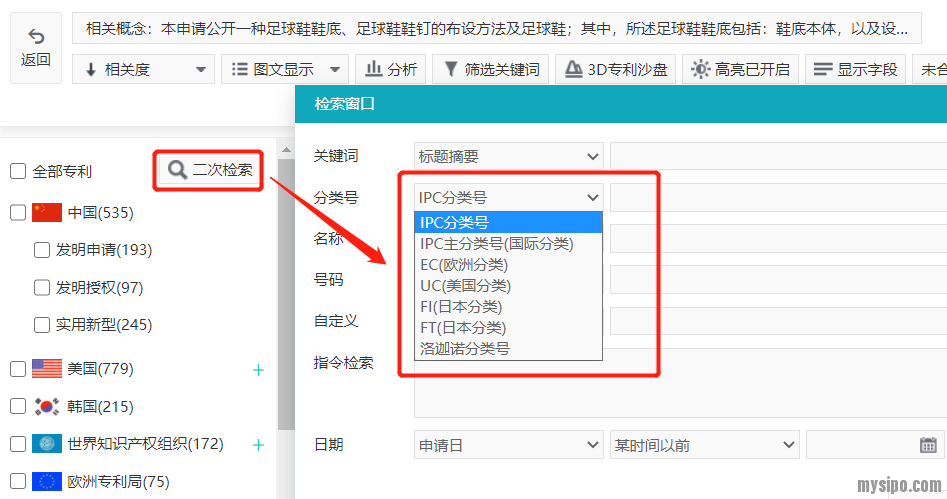
虽然主动选择项不包括,我们还是可以手动编辑来解决系统缺失CPC选项的问题。还是点击二次检索,而后在指令检索输入框中输入“CPC=?(?代表我们要检索的分类号)”就可以了,这里的指令检索输入框输入规则与高级检索页面的指令检索是完全一致的:
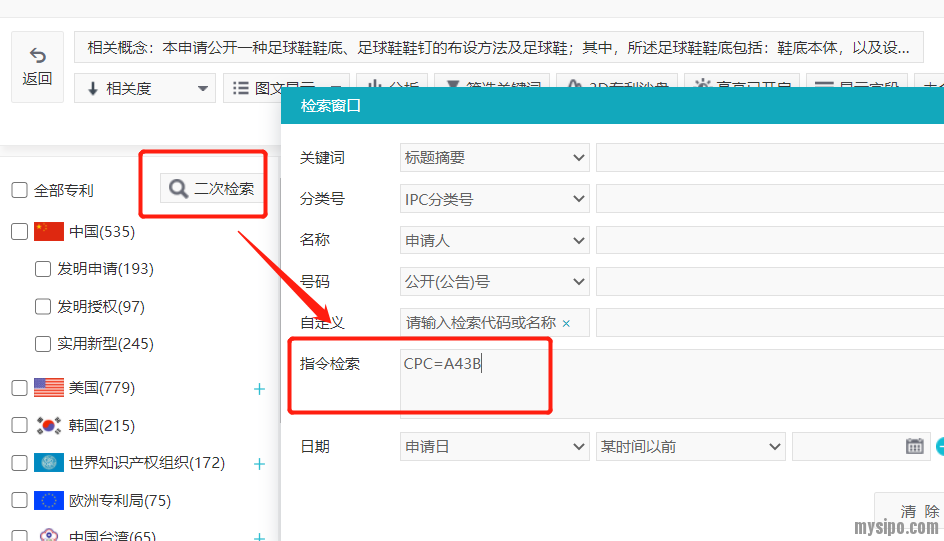
一连三段关于分类号的选择,因为各有不同而看着会有点乱,在这里我稍微总结一下。当我们使用合享的语义检索时,如果想同时限定分类号,有如下途径:
1.语义检索初始界面(只能选择IPC);
2.检索结果浏览界面(二次检索可主动选择IPC、EC、UC、FI、FT或LOC;不可选CPC);
3.检索结果浏览界面(二次检索可手动编辑CPC和其他任意分类号)
语义检索结果与输入要素的相似度是根据自己输入的要素准确性所决定的,这个道理同样也与关键词检索相通。以下分享部分自己常用的语义检索输入要素思路:
1.选择检索对象或申请人认为的具有创造性部分并进行语义检索;
2.选择原文权要/摘要、同族不同语言权要/摘要;
3.过于上位或外译内等其他原因导致的检索对象描述问题时,自行转述重要部分进行语义;
4.在3中,自行转述部分可以经deepl网页翻译成其他语言进行其他国家语义检索(用deepl是因为他翻译的风格比其他大多数翻译工具更像个人);
5.直接选取有用的实施例。
以上列举的我的常用的语义检索输入要素思路,在我于2020年12月23日晚在思博平台进行的检索主题直播“实例讲解:用试探性检索打开检索思路”中有介绍,在此不多解释,有需要的朋友们可以通过以下途径回看我的直播:
1.思博学院:(附带了直播课件可下载,需先注册思博账号)
https://www.mysipo.com/goods-detail/?goodsId=1315
2.B站:https://www.bilibili.com/video/BV1wX4y1K74r
以上常用的语义检索输入要素思路中,并不包括专利号的语义要素输入思路,因为输入一个号而已,其实没什么思路,我不可能告诉你们我在敲键盘时的心路历程。
其实语义检索和上期文章——“合享(incopat)数据库部分功能简介(1)”中简单介绍的超级排序会有一些类似。
1.语义检索初始界面(只能选择IPC);
2.检索结果浏览界面(二次检索可主动选择IPC、EC、UC、FI、FT或LOC;不可选CPC);
3.检索结果浏览界面(二次检索可手动编辑CPC和其他任意分类号)
语义检索结果与输入要素的相似度是根据自己输入的要素准确性所决定的,这个道理同样也与关键词检索相通。以下分享部分自己常用的语义检索输入要素思路:
1.选择检索对象或申请人认为的具有创造性部分并进行语义检索;
2.选择原文权要/摘要、同族不同语言权要/摘要;
3.过于上位或外译内等其他原因导致的检索对象描述问题时,自行转述重要部分进行语义;
4.在3中,自行转述部分可以经deepl网页翻译成其他语言进行其他国家语义检索(用deepl是因为他翻译的风格比其他大多数翻译工具更像个人);
5.直接选取有用的实施例。
以上列举的我的常用的语义检索输入要素思路,在我于2020年12月23日晚在思博平台进行的检索主题直播“实例讲解:用试探性检索打开检索思路”中有介绍,在此不多解释,有需要的朋友们可以通过以下途径回看我的直播:
1.思博学院:(附带了直播课件可下载,需先注册思博账号)
https://www.mysipo.com/goods-detail/?goodsId=1315
2.B站:https://www.bilibili.com/video/BV1wX4y1K74r
以上常用的语义检索输入要素思路中,并不包括专利号的语义要素输入思路,因为输入一个号而已,其实没什么思路,我不可能告诉你们我在敲键盘时的心路历程。
其实语义检索和上期文章——“合享(incopat)数据库部分功能简介(1)”中简单介绍的超级排序会有一些类似。
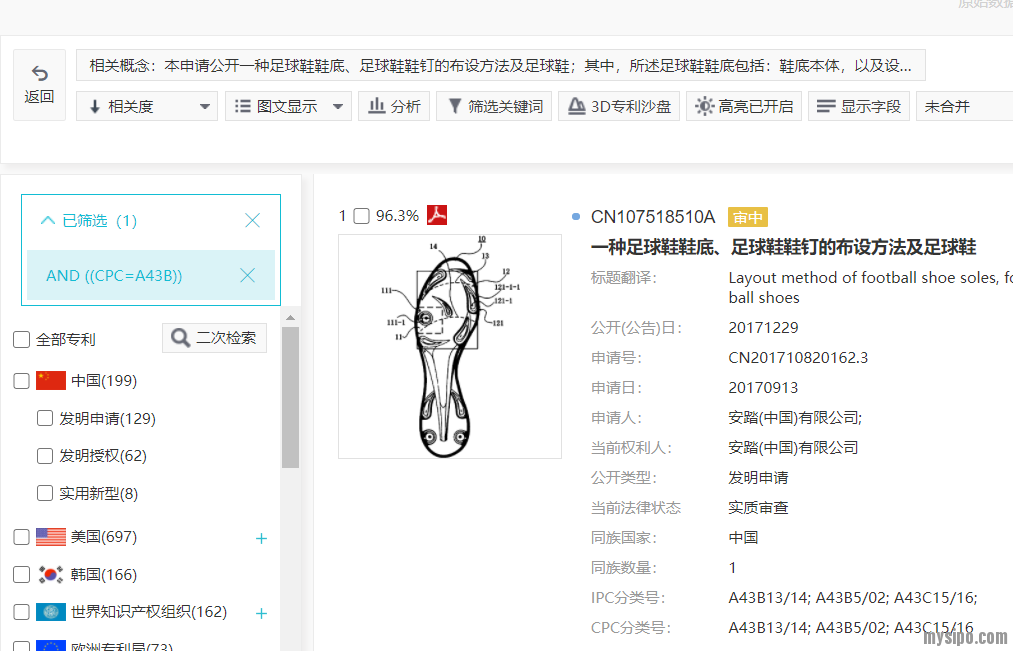
如上图,在超级排序中,我们如果输入的是专利号,并且不带任何的检索式,让系统在所有文献中按相似度排序,其相似准确度是接近于语义检索的。但这已经是超级排序的另类玩法,一般不这么做。如果这种玩法中,不是输入专利号而是输入文字,那么相似准确度可能会比较低。这也取决于我们输入的要素。
那么本文到这就结束了。往后几篇会介绍:
1.扩展检索
2.图形检索
3.算符
4.申请人官方商城
5.编辑区格式转换
6.检索历史
根据功能简介的丰满程度,有可能会合并若干功能介绍,敬请关注。
那么本文到这就结束了。往后几篇会介绍:
1.扩展检索
2.图形检索
3.算符
4.申请人官方商城
5.编辑区格式转换
6.检索历史
根据功能简介的丰满程度,有可能会合并若干功能介绍,敬请关注。

评论列表
- 暂无评论数据
快速回复
黑娃
版主








[福建省]
主题:209 回帖:5271 积分:89682
分享
收藏(1)
点赞
举报