我的公众号原文链接:https://mp.weixin.qq.com/s/_ePv8lEaPzxhBU0_6FKHQA
本文浅读的对象,为《专利有效性检索》书中的第三章第二节内容,作者为马天旗(原国家知识产权局专利局副处长)、赵星、欧阳石文。以下浅读、分析等均仅代表本人观点,不代表作者马天旗、赵星、欧阳石文观点。如有其他理解欢迎交流。
第三章总共四节内容,是按照专利有效性检索的基本流程排序的,分别为:
这一节分两部分,先讲检索要素的确定,在检索要素确定这一部分,主要针对的是核心和主要技术特征的确定;再讲检索要素的表达,表达主要是关键词和分类号表达,另外还有针对特殊检索要素的表达。
首先肯定的是针对核心和主要技术特征的确定这一思路。稍微学习过检索的都知道,检索大多时候是个先准后全的思路,即先查准后查全,而查准,首先针对的必然是主要技术特征。在这里作者给了一个图,“技术特征的梳理和分类”:
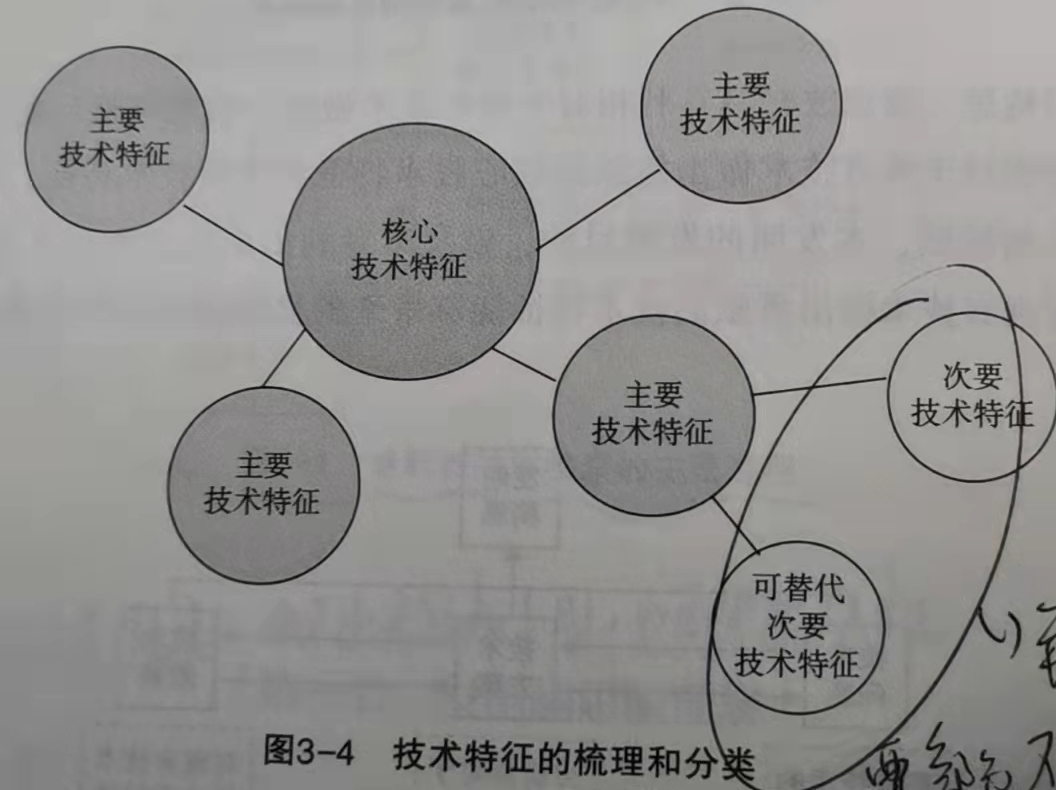
我们会梳理出全部的技术特征,并且结合领域、问题、功能效果去确定主要的技术特征和次要的技术特征。这一句经验平平无奇,主要关注作者以下阐述:“......首先将本专利声称的对现有技术做出贡献的主要技术特征归纳梳理出来......其他已经是现有技术的技术特征可以不作为主要的检索要素。[1]”
这句话强调两件事,一个是重视检索对象全文内容的分析,另一个是重视申请人的意图。一般我们说,一篇专利文献,它的背景技术描述的问题并不一定是真实存在的问题,或者说背景技术的描述充满主观性;而作者阐述的功能效果,也未必真的能实现,或者实际上无法实现那么好的功能效果。但所有的所有,经过分析后,都能转化为申请人的意图。
的确,申请人的阐述容易主观,或带着欺骗,但那正是申请人意图的体现,他希望我们关注哪里,那我们就关注哪里。他所指向的部分,正是该专利中他真正想保护的部分,或者说他的确认为有价值的部分。以下举个例子。

假如我们要对这篇专利做一次有效性检索。首先看看权1:

权1描述了一种踏步机,以“其特征在于”分为了明面上的前后两部分。但我们知道不能简单的这样认定“前”就是申请人意图中的现有技术,“后”就是申请人意图中的有价值的部分即主要技术特征。
看背景技术时发现,申请人似乎的确认为“前”就是现有技术:

但分析具体实施例时发现,申请人对于连动机构做了改进:

因此“前”的部分中,连动机构暂不认为是现有技术,而包括连动机构在内的其他的部分,都可以暂且认为是主要技术特征。这里说“暂且”是因为,分析申请人意图是判断主要技术特征的一个技巧,但并非决定性的技巧,比如我们不能忽略前文所述的基础技巧--“我们会梳理出全部的技术特征,并且根据领域、问题、功能效果去确定主要的技术特征和次要的技术特征”。
已经确认了主要技术特征,那么次要技术特征是不是就弃用了?不是的。次要技术特征仍会在以下具体情景中发挥作用:
2)当主要技术特征难以表达,辅助构建有检索价值的检索式
在找到主要技术特征之后,接下来就是检索要素的表达了,在此之前,作者给了一张表--“特征表达表”。可能有些人觉得这几个字陌生,那么换一种表达应该就熟悉了--“检索要素表”。这张表在很多书中都有,我就不贴出来了。这里就强调一点。大家在看的时候会注意到,表格中所有属于分类号或关键词的位置都被填满了,但实际操作中,哪些会填哪些不填、哪些先填哪些后填都是灵活处理的,并不是说,一开始就迫不及待立刻填满整张表,这是极其影响检索效率和思路的。
作者所阐述的检索要素的表达,主要是关键词和分类号表达,另外还有针对特殊检索要素的表达。但我们知道,能表达检索要素的,除了关键词和分类号,其实还有语义。鉴于篇幅有限,语义也不是本节重点,我就不展开阐述了,感兴趣的可以私聊我探讨语义检索的技巧。
作者给了一张表“关键词的表达维度和角度”,类似的表很多书里也有,我同样也就不贴出来了。我就挑一个我认为需要注意的点来聊聊。
关于表达角度“可能的错别字”。这一点我跟我学员也会讲到,但并非重点,为何?因为这一点跟汉语言的博大精深是脱不开关系的。我们可以假设存在错别字,但是不要字字计较,这特别影响效率。在我们拥有了一定检索经验,以及在检索阶段搜集到一些错别字之后,可以进行适当的扩展,这种时候是有必要的扩展。正常情况下,错别字发生在这些时候:
1)拼音或五笔等输入法错了(不太可能文中每个地方都错,我们用正确的文字是能检索到的)
2)行业/地方习惯或常见表达(很可能每个地方都是错别字,这需要通过检索浏览或加深现有技术了解来搜集扩展)
作者认为:“对于专利有效性检索而言,可以考虑先检索最准确的分类位置,然后再对其他不太准确的分类位置进行扩展检索。这是因为很多专利文献可能会分错位置,或者早期文献没有相对准确的分类位置。[1]”
这里体现两个思路,一个是先准后全,另一个是先挑有把握再选少把握。
1)先准后全。“先检索最准确的分类位置”体现了准,“对其他不太准确的分类位置进行扩展”体现了全。尤其是扩展检索,经常是对搜集中的分类号进行垂直扩展。
2)先挑有把握再选少把握。先检索准确的体现了先挑有把握,对不太准确的进行扩展体现了再选少把握。不太准确的分类位置所展现的分类号,其定位是“不太准确”,并非“完全不准确”,在项目时间允许的条件下,直接放弃不太准确的分类号检索,是不谨慎的,容易造成漏检。但选取了又会造成噪音。关于噪音部分,降噪就是了,降噪可以通过增加检索块、用算**化检索要素间位置联系、更精确化分类号和关键词等方式进行,这里不详述。
“很多专利文献可能会分错位置”,这是常见情况,但分错位置的专利文献比起总量而言仍然是九牛一毛,在有余力情况下,做查全时可以考虑补充这块分类号,但显然噪音会特别大,降噪办法如前文,不再赘述。或者还有一个小tip:用较为准确的关键词表达稍微弥补这类情况造成的漏检。
“早期文献没有相对准确的分类位置”,这同样是常见情况。分类表是每年更新一次或若干次的,更新次数因不同分类表而异,在这过程中,会有新增的分类号,用于细化旧分支或扩展新分支,这会使原本属于部分旧分类号的专利文献,在更新后被分到新的分类号中,当然在这过程中,也会产生分类员分错分类号位置的情况。
作者在此也给出了几种不同类型技术主题的IPC分类流程。大家可以根据IPC分类流程逆推分类号选取技巧。但总的来说,基本思路还是如前文所述,一个是先准后全,另一个是先挑有把握再选少把握。
至于特殊检索要素的表达,作者所用篇幅很少,而特殊领域也并非我所长,大家在看的时候若有疑问可以对应请教不同特殊领域(如涉及核苷酸或氨基酸序列)的检索大咖。
参考文献:
[1]马天旗,赵星,欧阳石文.专利有效性检索[M].北京:知识产权出版社,2021:33-41
















分享
收藏(6)
点赞
举报